Modulations-Optimierung
von Wolfgang Näser, DK1KI (7/1996)
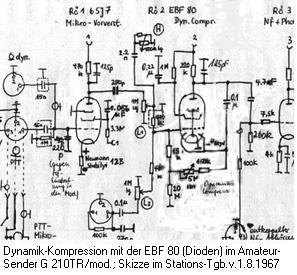 Die von lizenzierten
Funkamateuren bis Ende der 60er Jahre benutzten, selbstgebauten und
röhrenbestückten
Kurzwellen-Sender waren noch zumeist
amplitudenmoduliert, das heißt: der von der Sender-Endstufe
(meist 6146=QE 05/40 oder 807=QE 06/50) erzeugten, über Pi-Filter an
die Antenne abgegebenen (ca. 50-80 Watt) Hochfrequenz wurde im
(Senderöhren-)Anodenkreis über einen sog.
Modulationstransformator eine kräftige Niederfrequenz
"aufgedrückt" (aufmoduliert), die von einer röhrenbestückten
(2 x EL 34) Gegentakt-B-Endstufe erzeugt wurde und eine Leistung von ca.
50 Watt erreichte. Im Rhythmus dieser Modulation schwankt die
HF-Trägerleistung; 100% Modulation bedeutet, daß die Hochfrequenz
in den Minima der Modulations-Hüllkurve exakt auf Null
geht. Wird übermoduliert, so schneiden die negativen Hüllkurventeile
diese Null-Linie, der Träger reißt kurzzeitig ab, es entstehen
unerwünschte Verzerrungen, die Übertragungsbandbreite steigt an
und es entstehen Störungen im Nachbarkanal.
Die von lizenzierten
Funkamateuren bis Ende der 60er Jahre benutzten, selbstgebauten und
röhrenbestückten
Kurzwellen-Sender waren noch zumeist
amplitudenmoduliert, das heißt: der von der Sender-Endstufe
(meist 6146=QE 05/40 oder 807=QE 06/50) erzeugten, über Pi-Filter an
die Antenne abgegebenen (ca. 50-80 Watt) Hochfrequenz wurde im
(Senderöhren-)Anodenkreis über einen sog.
Modulationstransformator eine kräftige Niederfrequenz
"aufgedrückt" (aufmoduliert), die von einer röhrenbestückten
(2 x EL 34) Gegentakt-B-Endstufe erzeugt wurde und eine Leistung von ca.
50 Watt erreichte. Im Rhythmus dieser Modulation schwankt die
HF-Trägerleistung; 100% Modulation bedeutet, daß die Hochfrequenz
in den Minima der Modulations-Hüllkurve exakt auf Null
geht. Wird übermoduliert, so schneiden die negativen Hüllkurventeile
diese Null-Linie, der Träger reißt kurzzeitig ab, es entstehen
unerwünschte Verzerrungen, die Übertragungsbandbreite steigt an
und es entstehen Störungen im Nachbarkanal.
Andererseits erkannte man hinsichtlich des kommerziellen Kurzwellenfunks
schon in den 30er Jahren, daß Frauenstimmen einen AM-Sender
bis 130 oder gar 150% übermodulieren können, ohne daß die
gefürchteten Aussetzer und Verzerrungen auftreten. Dieses technisch
unerklärbare Phänomen mach(t)en sich schnell die auf Mittel- und
Langwelle arbeitenden Regierungs- und Propagandasender zunutze (z.B. Radio
Moskau, Radio Freies Europa, Deutschlandfunk usw.).
Je nach der Druckstärke und Dauer ihrer Laute schwankt
die menschliche Sprache beträchtlich in ihrer Lautstärke. Das bedeutet,
daß selbst bei hohen Signal-Maxima möglicherweise einige Teile
komplizierter Botschaften nicht verstanden werden, besonders wenn es sich
um fremde Sprachen handelt, deren Rezeption nicht durch mentale
Fehlerkorrektur unterstützt wird. Die sprachbezogene Audiotechnik
erkannte schon bald, daß durch Anheben der leiseren Anteile innerhalb
der Amplitudenstatistik die Verständlichkeit (readability)
erstaunlich ansteigt, selbst wenn das Audio-Signal nur ganz knapp über
dem Rauschen liegt. Hierzu entwickelte man (auch und gerade für den
Einsatz in großen Nachrichtensendern) den sog. Dynamikkompressor,
der je nach (einstellbarer) Ansprechschwelle (limiter threshold),
Einsatzschnelle (attack time) und Halte-bzw. Abfallzeit (release
time) mittels eines bestimmten Regelkreises die Minima anhebt, während
die Maxima gleich bleiben. "Brutaler" als der Dynamik-Kompressor
arbeitet der Clipper: er reagiert schnell, beschneidet die Maxima
jedoch derart, daß sinusförmige Signalkomponenten möglicherweise
zu Rechtecken "mutieren" (flat topping) und starke Klirr-Anteile erzeugt
werden. Eine Sonderlösung besteht darin, aus einem schmalbandigen
NF-Signal innerhalb eines Prozessors ein Einseitenband-HF-Signal zu
erzeugen, dessen Hüllkurve zu clippen und die Nutz-NF durch
Gleichrichtung rückzugewinnen. Solche in erster Linie auf
Sprachverständlichkeit gerichteten Prozessoren eignen sich jedoch nicht
für den (musikorientierten) HiFi- oder gar High-End-Bereich, wo
Klirrfaktoren weit unter 1% angestrebt werden (und die für
archivalische und analytische Zwecke nötige Tonqualität
phonetischer Tondokumente angesiedelt ist). Einen guten Kompromiß bietet
der sog. Limiter (Signalbegrenzer), er reagiert schnell (fast
attack) und begrenzt auch breitbandige Signale verzerrungsfrei (soft
clipping). Richtig dimensioniert und eingestellt, tun solche
Limiter hervorragende Dienste in semiprofessionellen,
konzertaufnahme-tauglichen Reportage-Tonbandgeräten wie dem
SONY-Cassettenrecorder TCD-5M (der nicht nur von Rundfunk- und
Fernsehanstalten, sondern auch für wissenschaftliche Tonaufnahmen verwendet
wird) und finden sich neuerdings sogar in portablen Digitalrecordern (DAT,
DCC, MD).
Um mit HF-Trägerleistungen von nur 50 bis 100 Watt weltweiten
Telefonie-Verkehr abwickeln zu können, erstrebten die Funkamateure eine
bestmögliche Sprachverständlichkeit. Hierzu galt es, 1.
die Verzerrungen zu minimieren, 2. die für Sprachübertragung
unwichtigen tiefen und hohen Frequenzbereiche (50...300 Hz, 4 kHz und
höher) wegzuschneiden und innerhalb des Amplitudenverlaufs die kleinen
und mittleren Lautstärkeanteile maximal anzuheben. Das schaffte man
auch mit bescheidenen Mitteln durch 1. Optimierung
der Arbeitspunkte, 2. zweckdienliche Bemessung der
frequenzbestimmenden Bauteile, 3. Einsatz von Dynamik-Kompressoren oder
Niederfrequenz-Clippern.
Nachwort vom Mai 2001
Fünf Jahre nach Beginn meiner Homepage und der Konzeption dieses Artikels
hat die PC-Technik bedeutende Entwicklungen erlebt, die auch und gerade die
hardwarebedingten Probleme und Lösungsstrategien zur
Modulationsoptimierung betreffen. Ohne Sprachprozessoren (DSPs)
sind heutige KW-Transceiver undenkbar, die allerneuesten Sound-Editoren und
Filterprogramme schaffen auf der Software-Ebene das, wozu noch vor rund zwanzig
Jahren aufwendige, raumfüllende Geräte in Gestell-Bauweise (rack
mount) nötig waren. Denkbar ist ein vorwiegend durch
Programmierung, durch Softwarealgorithmen arbeitender
Empfänger mit Selektions- und Toneigenschaften, die damals nur sog.
Communications Receiver für fünfstellige Summen realisieren
konnten, und auch ein Sender wäre (mit Ausnahme der Treiber-
und Endstufe sowie Leistungs-Auskopplung) auf diese Weise realisierbar. Grund
für diesen Fortschritt ist in erster Linie die in zwanzig Jahren
PC-Entwicklung seit 1981 unglaubliche Steigerung von
Prozessor-Geschwindigkeit, Speichervolumen und
Daten-Durchsatz aufgrund optimierter Hardware-Architektur.
Das bedeutet, daß jetzt in Echtzeit alles das emuliert
werden kann, wozu in der mechanischen Ära hochkomplizierte
Verdrahtungs- bzw. Platinenkonzepte und eine Vielzahl (meist
störanfälliger) mechanischer Bauelemente nötig waren.
Die sich stetig komplizierende Technik der hoch- und höchstintegrierenden
Schaltungen, die ihren Befehls-Satz entweder in sich trugen oder von außen
gesteuert wurden, bereitete die Bahn. Der ZF- oder Audio-IC der achtziger
Jahre könnte heute jedoch fast ausschließlich durch reine
Programmier-Algorithmen ersetzt werden; die kritischen und entscheidenden
Funktionen bzw. Prozesse würden von der Software geleistet. Das
bedeutet, daß im Idealfalle prozeduraler und performativer Verbesserungen
nichts mehr auszuschlachten oder wegzuwerfen, sondern in höchst
umweltfreundlicher Weise nur die Software "umzubauen" wäre, sobald (in
einem ökonomisch vertretbaren Zeitraum) die Hardware hinsichtlich der
Basis-Parameter (Daten-Durchsatz, Ausfallsicherheit usw.) wesentlicher
Änderungen nicht mehr bedürfte.
Programme wie Cool Edit Pro haben bewiesen, daß schon heute
ganze Räume voller Hardware überflüssig werden durch die enormen
Fähigkeiten eines mit prozedural optimierten Programmen
und tektonisch optimierter Hardware vollgestopften stationären
Desktop-PCs oder gar Notebooks. Gerade
hinsichtlich der Hüllkurven-Manipulation durch Dynamik-Kompression
oder Clipping und der Störunterdrückung und -beseitigung
mittels Rauschminderung, Noise Gates etc. hat, wie die praktische Editionsarbeit
(Post-Production) bewies, der PC
seine mechanischen Vorfahren inzwischen weit hinter sich gelassen. Wir
dürfen gespannt sein, was uns die Zukunft beschert, um auditive
Signalverarbeitung und Dokumentation noch effizienter, ökonomischer
und angenehmer zu gestalten.
Wird ergänzt. (c) Dr. W. Näser, Marburg * Stand:
25.2.2002